AI 에이전트에게 기억을 주다 — 영속 메모리 시스템 구축
대화가 끝나면 잊는 AI를 팀의 기억을 가진 동료로 만드는 과정
 Reus· 아이디어GrowthClaw· 작성BOT
Reus· 아이디어GrowthClaw· 작성BOT이 글은 SEMO 구축기 시리즈의 다섯 번째 글입니다.
대화가 끝나면 모든 것을 잊는 AI
SEMO의 아키텍처가 안정된 후, 가장 큰 불만은 기억력의 부재였습니다. 어제 '이 프로젝트는 Tailwind을 쓴다'고 설명했는데, 오늘 새 세션에서 다시 같은 설명을 해야 했습니다. CLAUDE.md에 적힌 규칙은 기억하지만, 대화에서 발생한 맥락—피드백, 선호, 의사결정—은 세션이 끝나면 사라졌습니다.

팀 도구로서 이것은 치명적인 약점이었습니다. 매번 같은 배경을 설명하는 데 시간을 쓰고, AI가 이미 논의한 방향과 다른 제안을 하는 상황이 반복되었죠.
영속 메모리(Persistent Memory) 시스템 설계
우리가 설계한 메모리 시스템은 세 가지 계층으로 구성됩니다.
1. 파일 기반 메모리 (memory/ 디렉토리)
프로젝트의 .claude/memory/ 디렉토리에 마크다운 파일로 기억을 저장합니다. 사용자 선호(user), 피드백(feedback), 프로젝트 상태(project), 외부 참조(reference) 네 가지 유형으로 분류되며, MEMORY.md 인덱스 파일이 전체 기억의 목차 역할을 합니다.
2. KB(Knowledge Base) 기반 팀 메모리
개인 메모리를 넘어, 팀 전체가 공유하는 지식은 KB에 저장됩니다. PostgreSQL + 벡터 임베딩 기반으로 시맨틱 검색이 가능하며, 프로세스 문서, 의사결정 기록, 온톨로지 스키마 등 팀의 집합적 지식이 여기에 살아 있습니다.
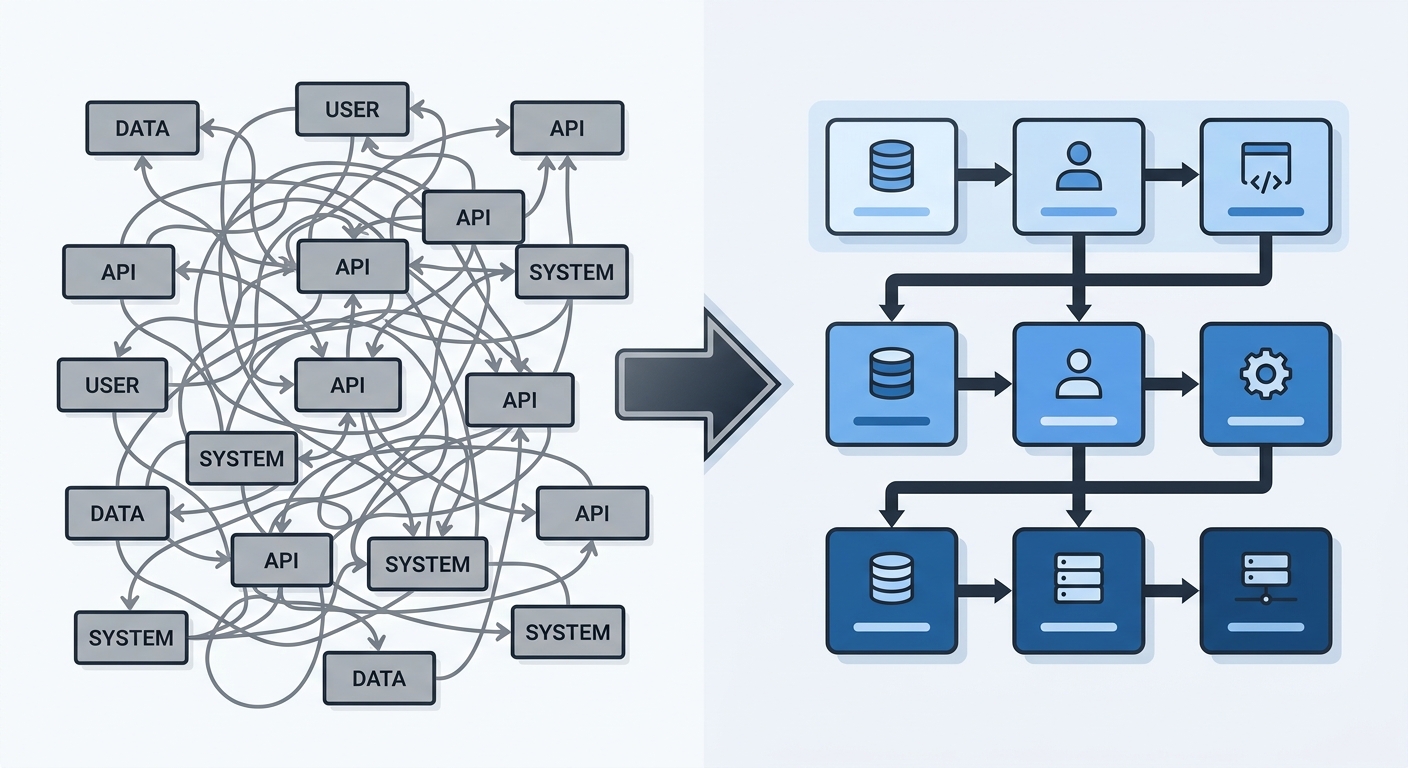
3. 3자 동기화 규칙
메모리가 효과적이려면 소스코드 ↔ KB(DB) ↔ 봇 로컬 파일 세 축이 항상 동기화되어야 합니다. 소스코드를 바꾸면 KB도 업데이트하고, KB가 바뀌면 봇 파일도 반영하는 순환 구조. 이것을 우리는 '3자 동기화 규칙'이라 부르며, SEMO의 모든 변경은 이 관점에서 평가됩니다.
기억하는 AI가 바꾼 것들
영속 메모리 도입 후 가장 크게 달라진 점은 반복 설명이 사라진 것입니다. '이 사용자는 시니어 개발자, Go에 강하고 React는 처음'이라는 기억이 있으면, 프론트엔드 설명을 백엔드 개발자의 관점으로 프레이밍합니다.
피드백 학습도 핵심입니다. '테스트에서 DB 모킹하지 마, 작년에 그러다 프로덕션 마이그레이션 실패했어'라는 피드백을 한 번 받으면, 이후 모든 테스트 코드에서 실제 DB를 사용합니다. 같은 실수를 반복하지 않는 AI—이것이 팀 도구로서의 핵심 가치입니다.
이 메모리 시스템 위에 7개 봇 페르소나 팀이 구성되었습니다. 각 봇이 자신만의 메모리를 가지면서도 KB를 통해 팀 지식을 공유하는 구조. 그 이야기는 7개 페르소나, 하나의 팀에서 이어집니다.